Generation AI
Democratizing Data + AI to every user
This document serves as a summary of the different announcements of DAIS 2023.
Contributors:
Data Engineering
Delta Lake 3.0
Delta Kernel
Delta Kernel simplifies the ecosystem by offering a single abstracted implementation of the Delta protocol and reducing fragmentation. It significantly reduce the time needed to connect data systems and maintain those connections

Delta UniForm
Delta Universal Format eliminates the need for customers to standardize on a single storage format. With UniForm, Delta will work with all Iceberg Hudi readers and writers, so teams don’t need to worry about converting or reformatting data to work with different query engines.

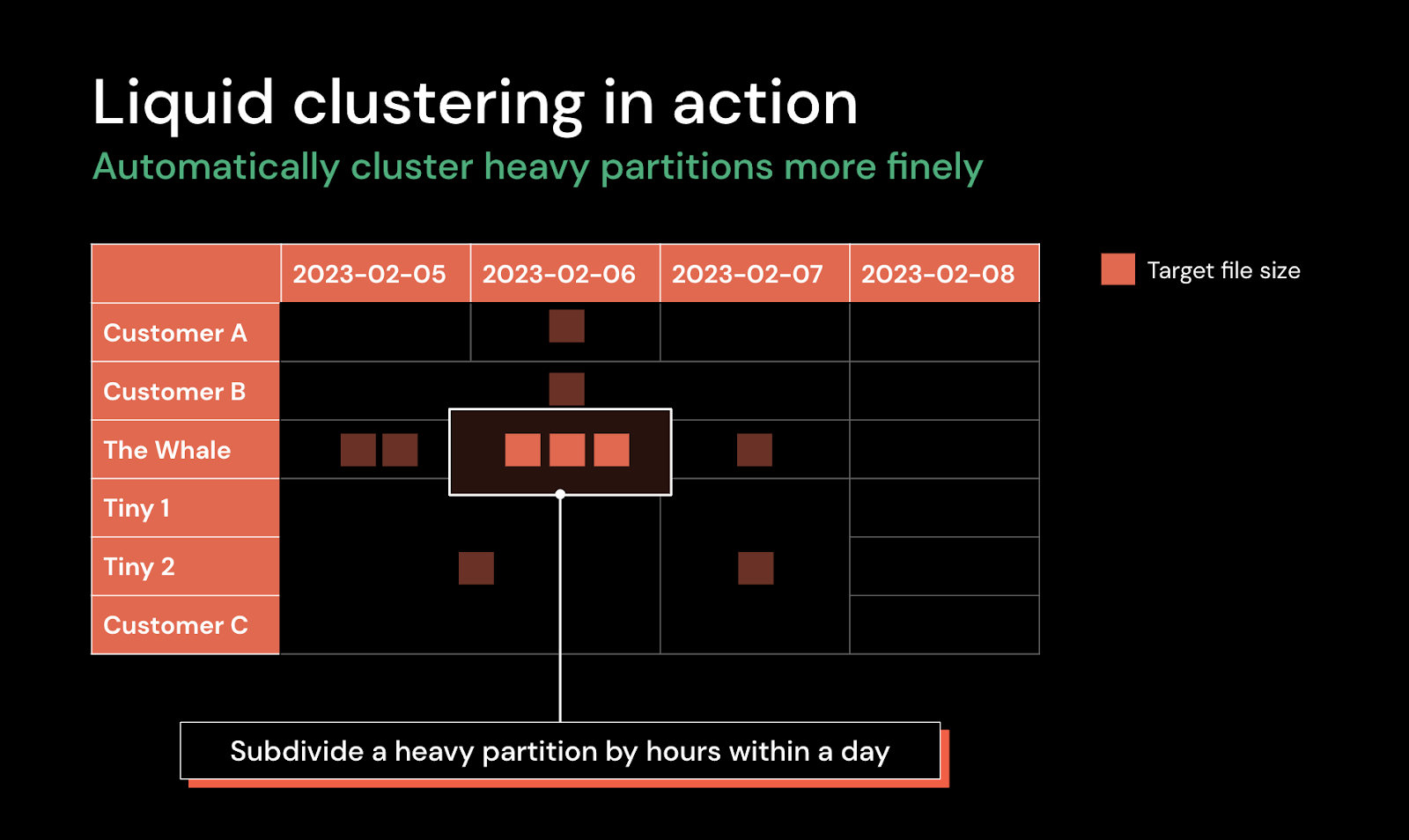
Liquid Clustering
Liquid clustering is an innovative technique to organize data layout to support efficient query access and reduce data management and tuning overhead. It’s flexible and adaptive to data pattern changes, scaling, and data skew.
For more information about Delta 3.0, check out this blog
Project Lightspeed
Here is a summary of all the available and upcoming new features:
Delta Live Tables in Unity Catalog (Public preview)
Databricks is bringing the power of Unity Catalog to data engineering pipelines. Delta Live Tables can now be governed and managed alongside with other Unity Catalog assets.
Workflows
Serverless compute
Serverless compute – Abstract away cluster configurations for data engineers and make ETL and orchestration more simple, scalable and cost-efficient. (Private Preview)
Enhanced control flow for Workflows
Enhanced control flow for Workflows – Allow users to create more sophisticated workflows fully parameterized, executed dynamically and defined as modular DAGs for higher efficiency and easy debugging.
Orchestration across teams
Orchestration across teams – The ability to manage complex data dependencies across organizational boundaries.
Easy CI/CD and Workflows as code
Easy CI/CD and Workflows as code – Introducing a new end-to-end CI/CD flow and the ability to express Workflows as Python.
Spark English SDK
The English SDK simplifies Spark development process by offering the following key features:
- Data Ingestion: The SDK can perform a web search using your provided description, utilize the LLM to determine the most appropriate result, and then smoothly incorporate this chosen web data into Spark—all accomplished in a single step.
- DataFrame Operations: The SDK provides functionalities on a given DataFrame that allow for transformation, plotting, and explanation based on your English description. These features significantly enhance the readability and efficiency of your code, making operations on DataFrames straightforward and intuitive.
- User-Defined Functions (UDFs): The SDK supports a streamlined process for creating UDFs. With a simple decorator, you only need to provide a docstring, and the AI handles the code completion.
- Caching: The SDK incorporates caching to boost execution speed, make reproducible results, and save cost.

For more information, check out this blog.
Data Governance & Data Sharing

Marketplace (GA)
Here is a summary of all the available and upcoming new features:
- AI Models in Databricks Marketplace
- Open Website accessible by everyone
- Private exchange
What’s next :
- Marketplace usage System table
- Solution accelerators
- Sharing volumes
Cleanrooms (Public preview)
With DB Cleanrooms participants can share and join their existing data and run complex workloads in any language on the data while maintaining data privacy. You don’t need to replicate the data with delta sharing. Cleanrooms on the Databricks Lakehouse Platform are scalable to multiple participants on any cloud or region. It is easy to get started.

Lakehouse applications (Coming Soon)
A Databricks App runs directly on a Databricks instance,and can integrate directly with the data, Data never has to leave the account. Databricks app can use and extend Databricks services like Jobs and ML features. Users can interact with the app through single sign-on, all while ensuring the highest standards of security, privacy, compliance, and scalability.
Delta Sharing
Here is a summary of all the available and upcoming new features:
Sharing notebooks (GA)

View Sharing (Public Preview)

Sharing Schemas
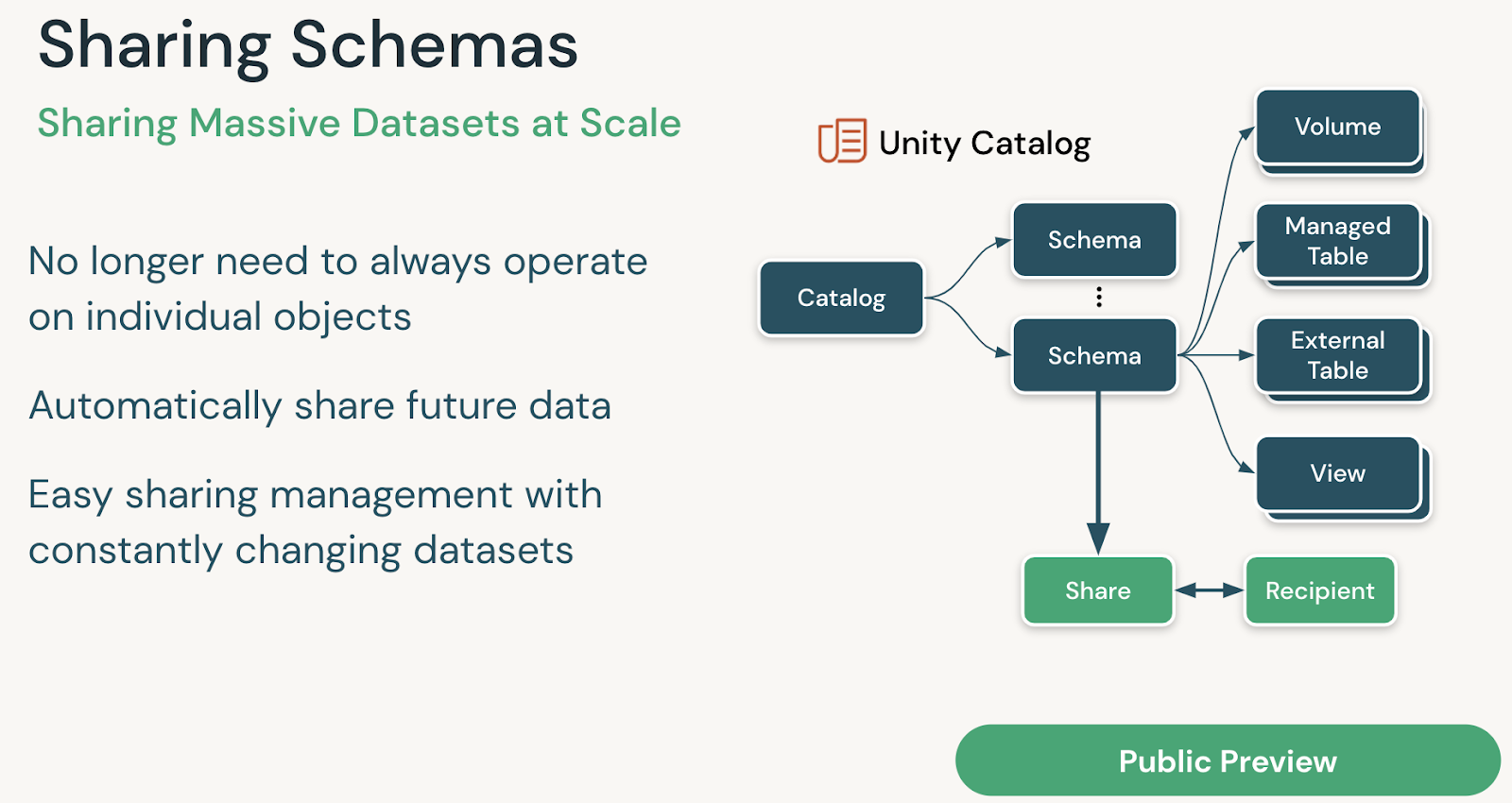
Volumes for files (Private Preview)

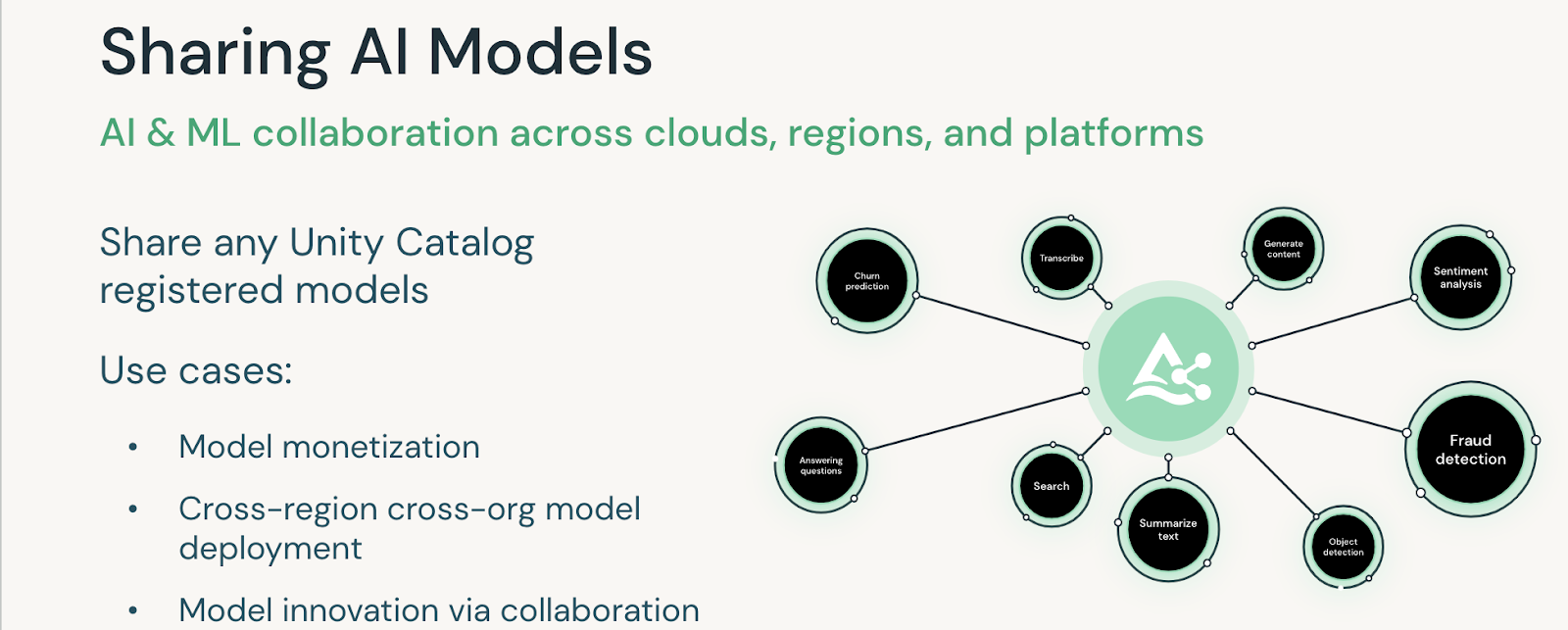
Sharing AI Models
Lakehouse federation (Public preview)
Lakehouse Federation in Unity Catalog allows users to seamlessly discover, query, and govern data from various sources such as BigQuery, MySQL, Postgres, Redshift, Snowflake, SQL Server, Synapse and more. This significantly speeds up ad-hoc analysis and prototyping for your data, analytics, and AI use cases, all within a unified and simplified experience.
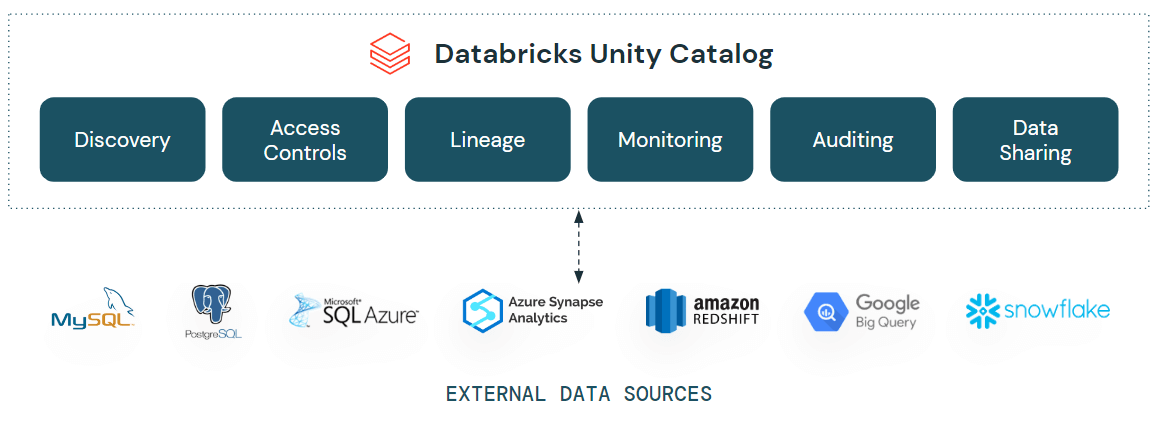
For more information about Lakehouse federation, check out this blog.
Volumes in Unity Catalog (Public preview)
Volumes are a new type of object that catalog collections of files in Unity Catalog and help you build scalable file-based applications that read and process large collections of data irrespective of its format, including unstructured, semi-structured, and structured. This enables you to manage, govern and track lineage for non-tabular data along with the tabular data in Unity Catalog, providing a unified discovery and governance experience

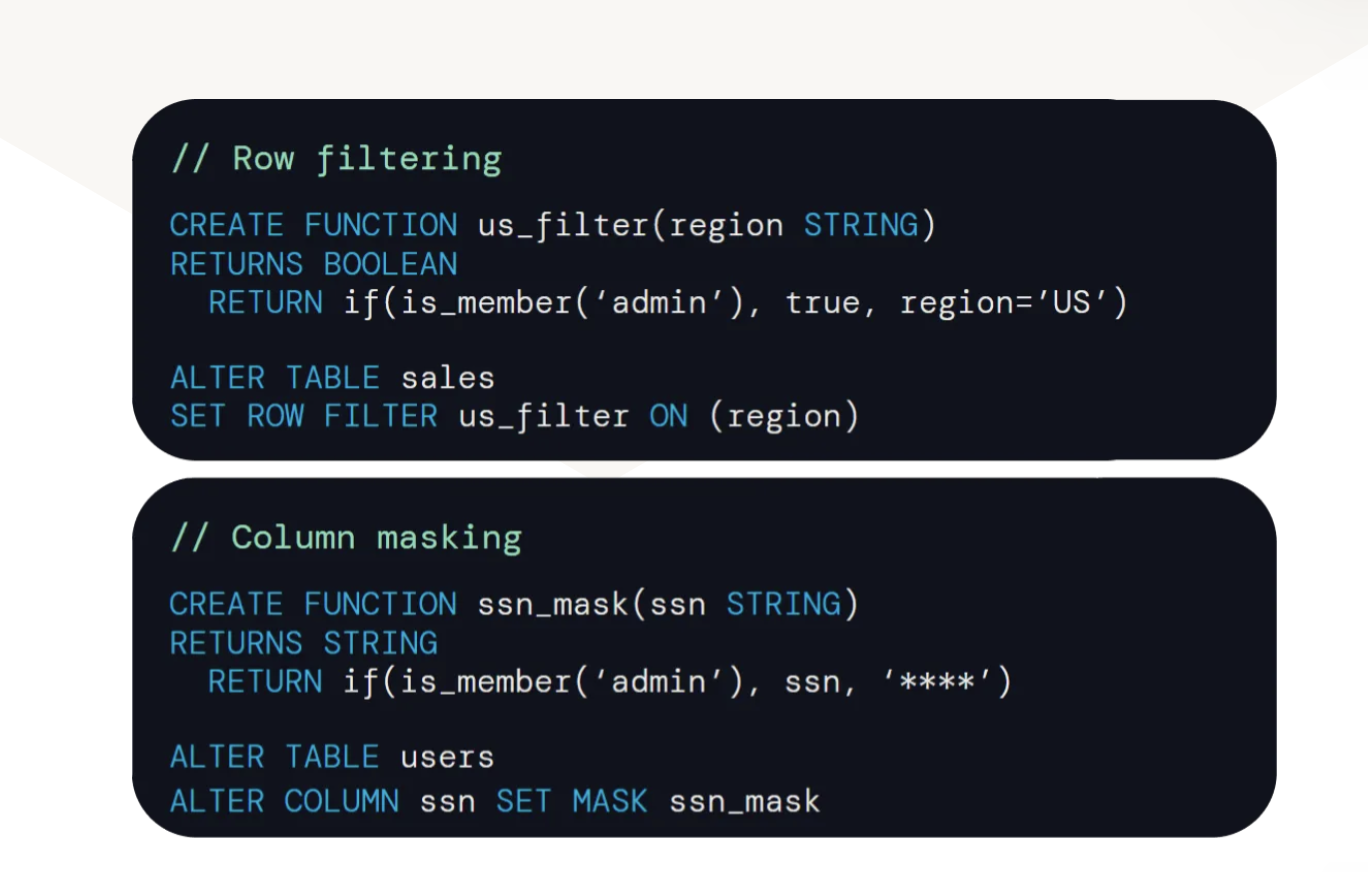
Fine grained access controls for Rows and Columns (Public Preview)
Row filtering and column masking in Unity Catalog will enhance data security effectively at the granular level. Users can leverage standard SQL functions to define row filters and column masks, enabling fine-grained access controls at the level of individual rows and columns.
Apache Hive Interface for Unity Catalog (Private Preview)
Hive Metastore (HMS) interface for Databricks Unity Catalog, which allows any software compatible with Apache Hive to connect to Unity Catalog.

For more information, check out this blog.
Feature Store and Model registry in Unity Catalog (Public Preview)
Models can now be managed with Unity Catalog (UC), extending unified governance to your ML models, and allowing you to share models across workspaces to simplify MLOps workflows

System tables (Public preview)
System Tables serve as a centralized analytical store for all operational data within Databricks, enabling powerful historical observability that connects the dots across multiple previously disconnected product areas and lets you answer key operational questions for your business. They provide comprehensive cost and usage analytics, offering valuable insights into resource consumption and expenditure. Additionally, System Tables empower all admin-approved Lakehouse users, including engineers, analysts, and scientists, to perform audit analytics for jobs, notebooks, clusters, and SQL/ML endpoints, allowing them to track data lineage and access permissions. Powered by Unity Catalog, this self-service analytics can be scoped appropriately to users’ projects/scopes, allowing your business to stay agile while meeting its compliance requirements.
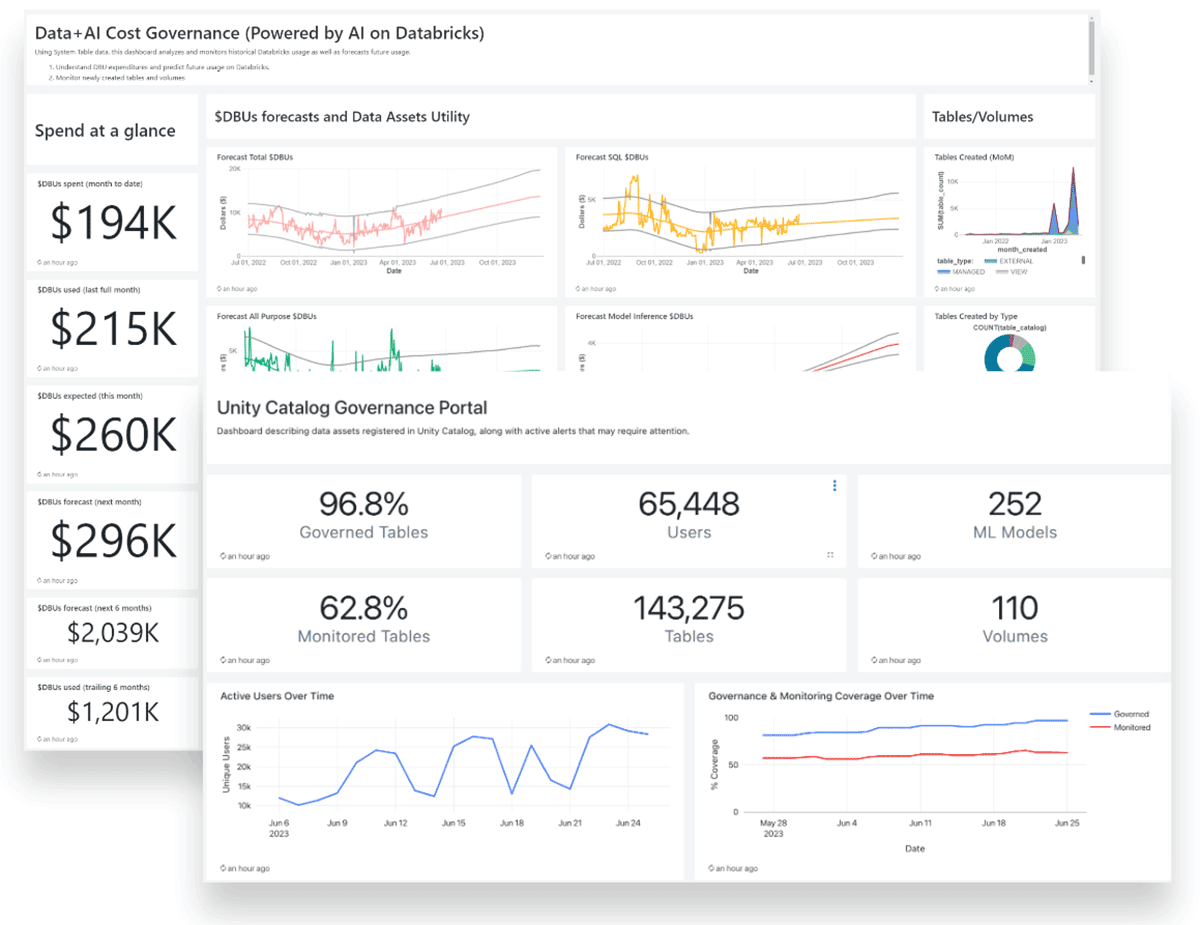
Check out public dbdemos.ai sample notebooks here
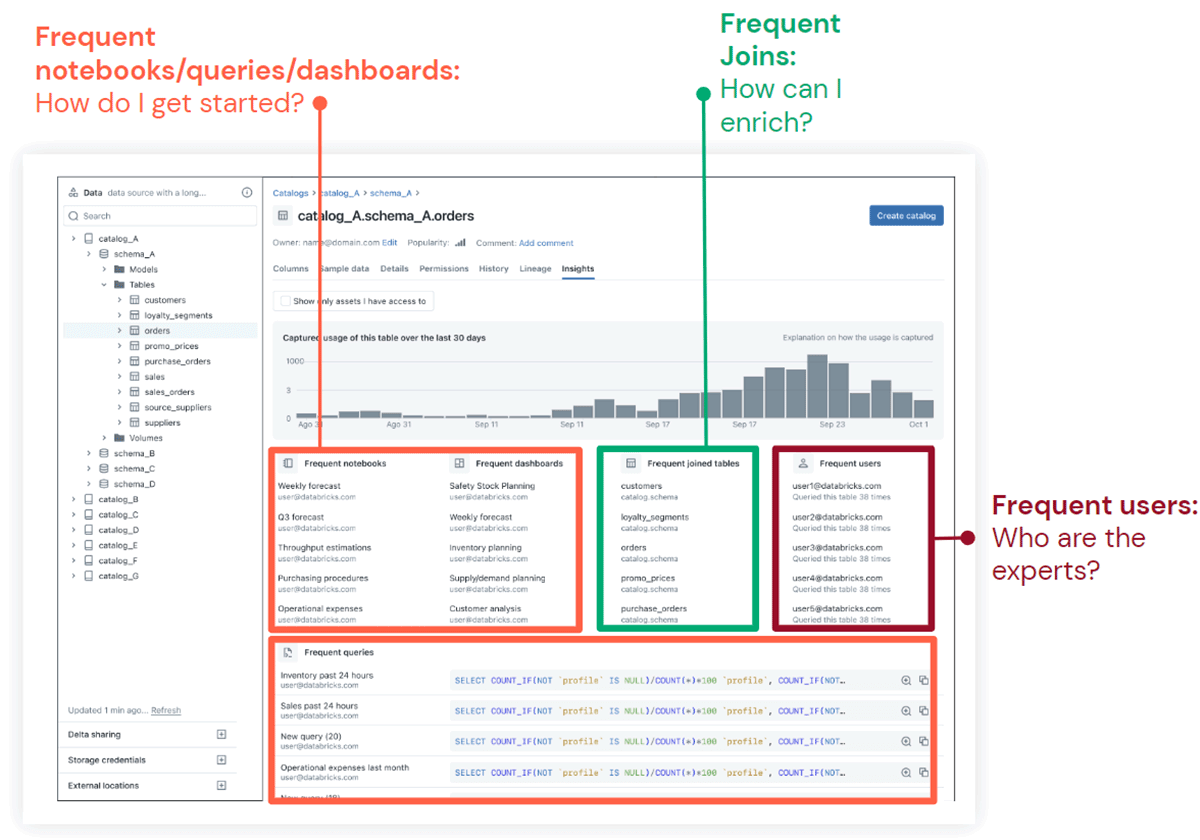
Tags and Classification
Unity Catalog goes beyond just discovery and provides contextual insights about the data, enabling users to jumpstart their work and accelerate analytics and AI initiatives. Users can easily describe and tag data assets to improve understanding, gain insights into the popularity of an asset, identify domain experts, and frequently used notebooks/queries/joins, making data enrichment a breeze.
Data Warehousing
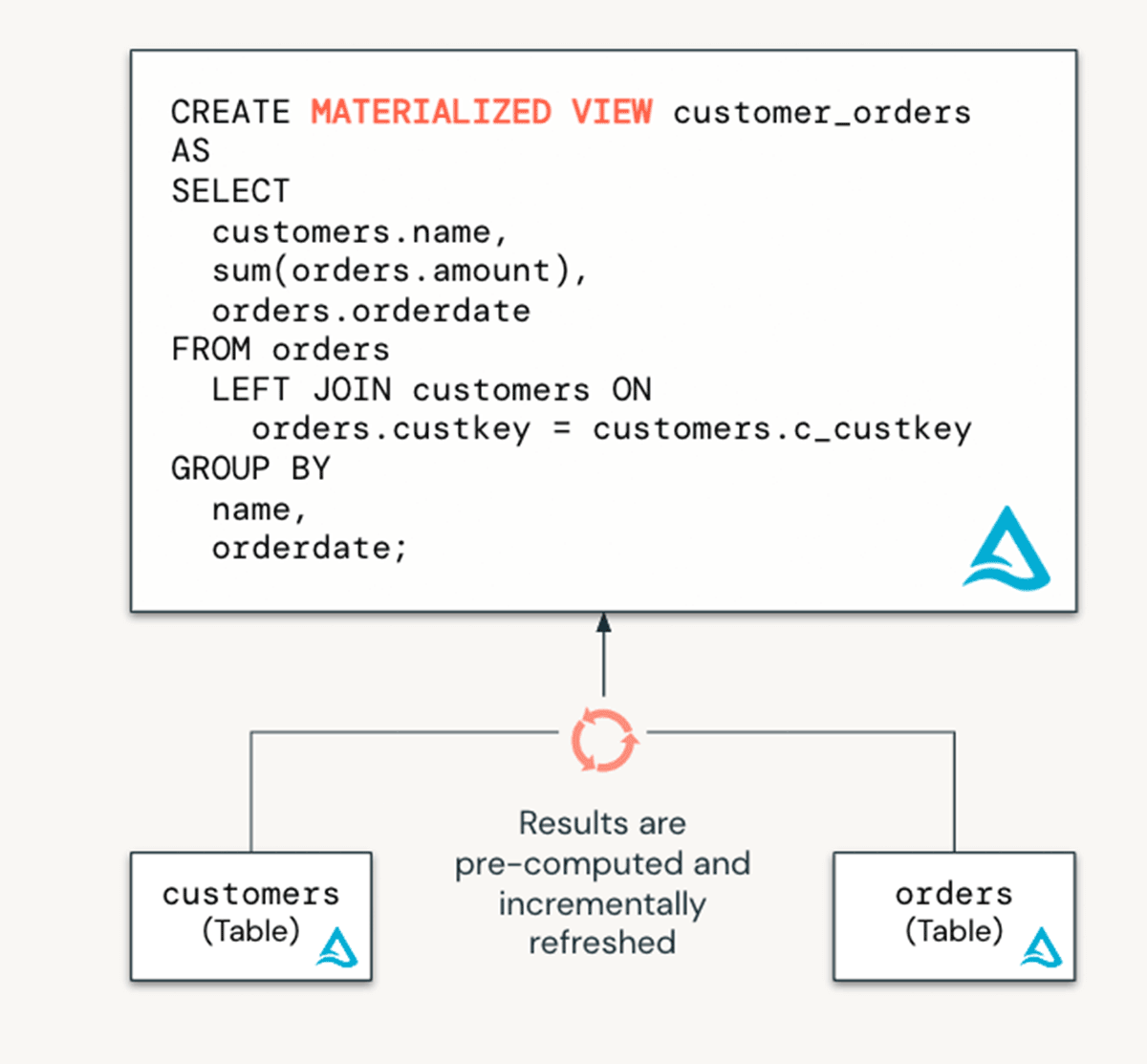
Materialized Views (Public Preview)
Materialized views reduce cost and improve query latency by pre-computing slow queries and frequently used computations.
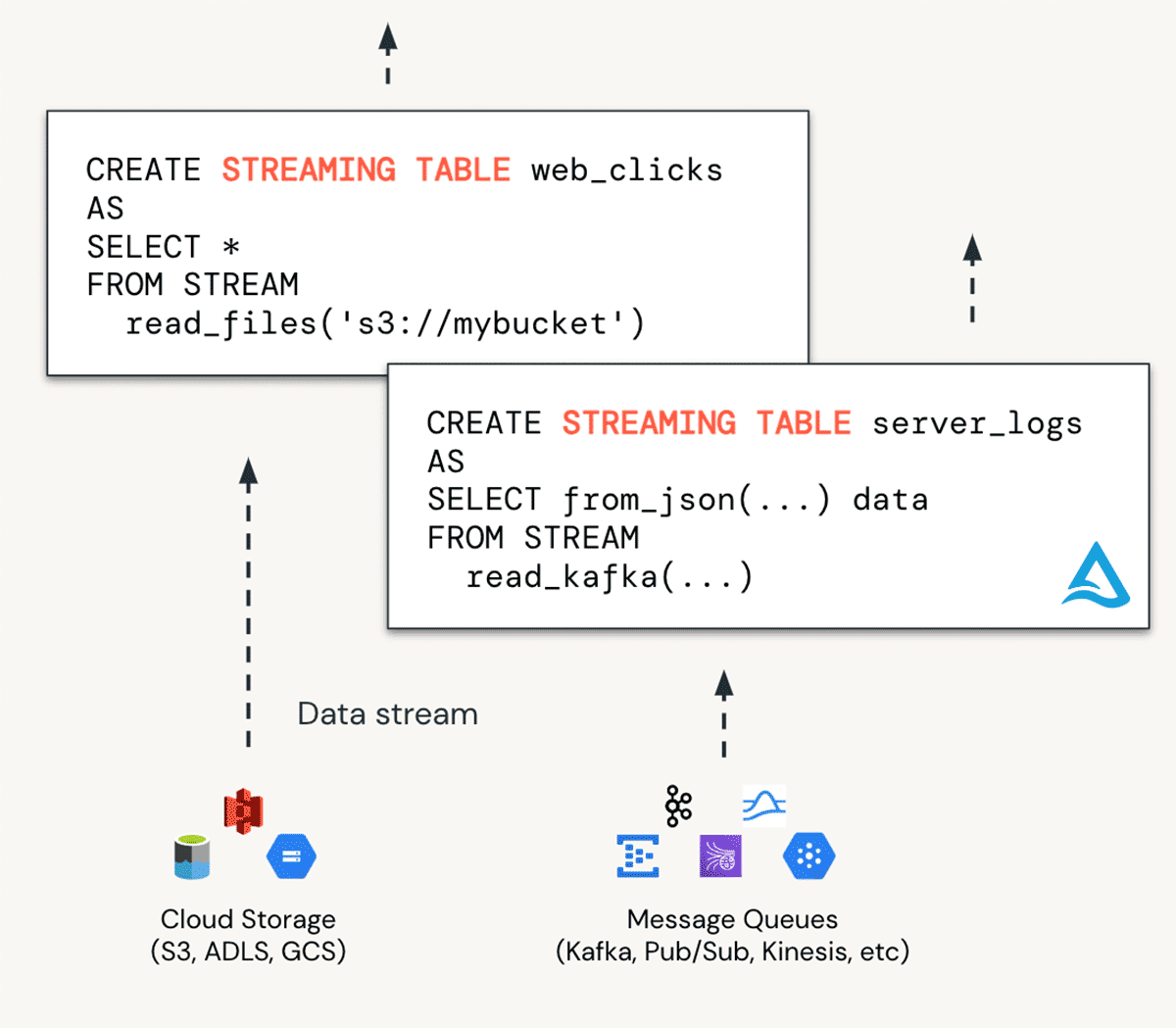
Streaming Tables (Public Preview)
Streaming Tables handles the Ingestion in DBSQL. They are ideal for bringing data into bronze tables and enable the scalable continuous ingestion from any data source including cloud storage and more.
Intelligent workload management
Continuously learning from workloads history to determine if it should prioritize a new query to run immediately or scale up to run it without disrupting running queries
Predictive Optimizations
A feature that learns based on your workload, and chooses the right file sizes for compaction, clustering, and stats collection.
Predictive IO
AI-driven intelligent query allocation prevents cluster over-subscription, keeping queries fast; meanwhile, ensuring maximum utilization of the underlying hardware
Machine Learning
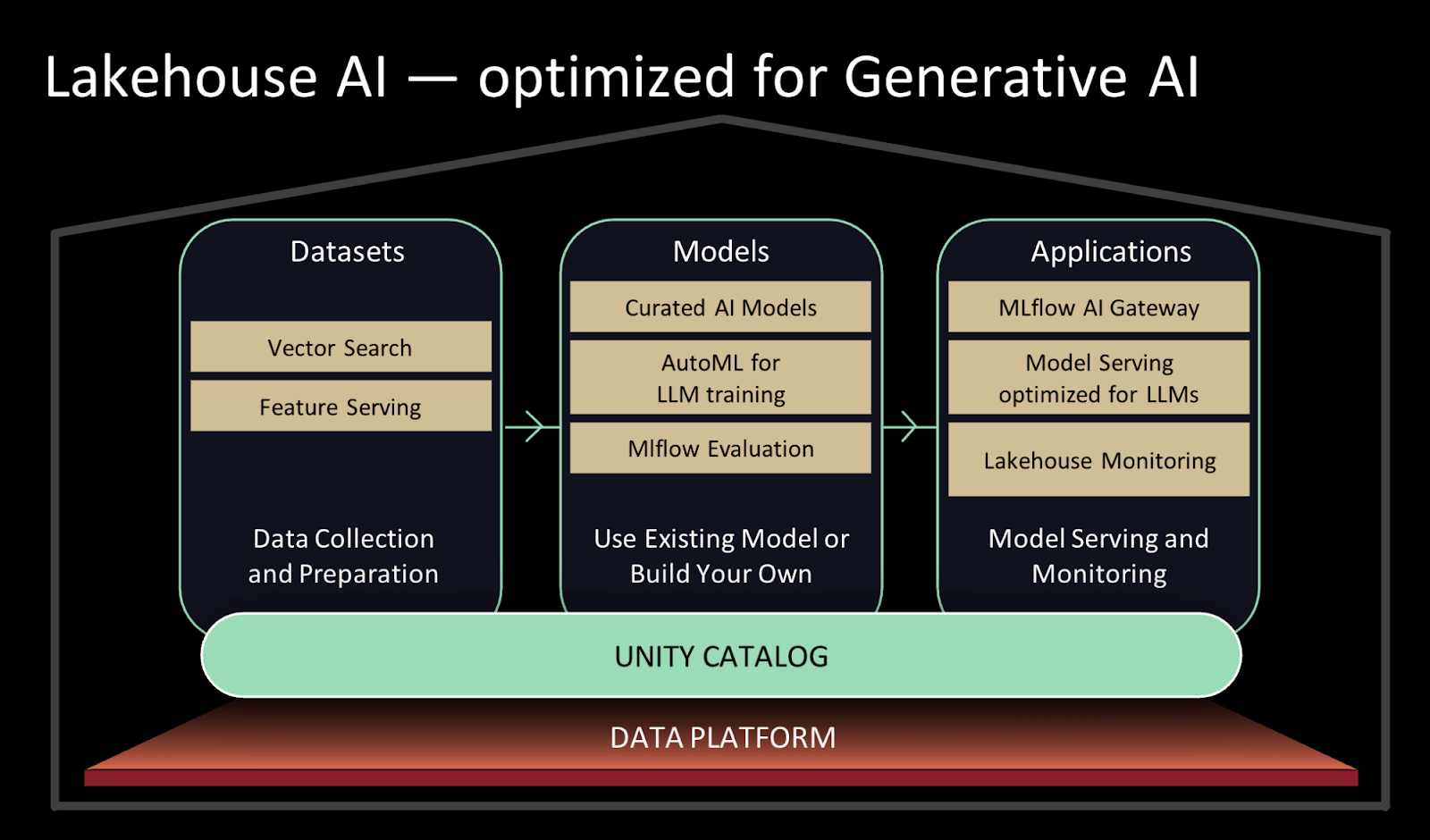
Lakehouse Monitoring (Public Preview)
Databricks Lakehouse Monitoring is an AI-driven monitoring service that encompasses the entire data pipeline, including data, ML models, and features. By eliminating the need for additional tools and reducing complexity, this innovative service, powered by Unity Catalog, brings a seamless experience to our users.
- PII Detection and auto tagging
- Expand DLT expectations to any delta table
LakehouseIQ
It’s a knowledge engine that learns the unique nuances of your business and data to power natural language access to it for a wide range of use cases. Any employee in your organization can use LakehouseIQ to search, understand, and query data in natural language. LakehouseIQ uses information about your data, usage patterns, and org chart to understand your business’s jargon and unique data environment, and give significantly better answers than naive use of Large Language Models (LLMs).
Natural language processing:
The first AI surface most Databricks users will see is the new Assistant in our SQL Editor and Notebooks that can write queries, explain them, and answer questions. It is already saving our users hundreds of hours of time. The Assistant relies heavily on LakehouseIQ to find and understand the right data for each activity and give accurate answers.
Search with LakehouseIQ :
LakehouseIQ also significantly enhances Databricks’ in-product Search. Our new search engine doesn’t just find data, it interprets, aligns and presents it in an actionable, contextual format, helping all users get started with their data faster.
Management and troubleshooting :
We are integrating LakehouseIQ into many of the management workflows in the Lakehouse. For example, providing meaningful comments on datasets gets easier with automatic suggestions – and the more documentation you add, the better LakehouseIQ will be able to use that data. LakehouseIQ can also understand and debug jobs, data pipelines, and Spark and SQL queries (e.g., tell you that a dataset may be incomplete because an upstream job is failing), helping users figure out when something is wrong.
LakehouseIQ API:
Exposing the main capabilities of lakehouseIQ through an API, including integrations in LLM application frameworks like LangChain. Your AI apps will be able to converse with your data and documents on the Lakehouse in natural language to build rich, grounded applications for your business.

For more information about LakehouseIQ, check out this blog.
Vector Search for indexing
With Vector Embeddings, organizations can leverage the power of Generative AI and LLMs across many use cases, from customer support bots by your organization’s entire corpus of knowledge to search and recommendation experiences that understand customer intent. Our vector database helps teams quickly index their organizations’ data as embedding vectors and perform low-latency vector similarity searches in real-time deployments. Vector Search is tightly integrated with the Lakehouse, including Unity Catalog for governance and Model Serving to automatically manage the process of converting data and queries into vectors
AutoML to build custom LLMs
Simple guided experience for creating models that know how to map input text data to your domain-specific categories.Easily apply the model for batch inference or realtime serving on Databricks. Text classification is useful for document categorization, tag generation, sentiment analysis, etc
See excellent 40 min recorded session with live demo by Eric Peter & Joseph Bradley
https://www.databricks.com/dataaisummit/session/llmops-everything-you-need-know-manage-llms/
Unified Data & AI Governance
We are enhancing the Unity Catalog to provide comprehensive governance and lineage tracking of both data and AI assets in a single unified experience. This means the Model Registry and Feature Store have been merged into the Unity Catalog, allowing teams to share assets across workspaces and manage their data alongside their AI
GPU Serving optimized for LLM
Providing optimized GPU model serving by improving performance over base model serving. These optimizations provide very low latency, allow teams to save costs at inference time, as well as allow endpoints to scale up/down quickly to cover the traffic.
GPU Serving
Deploy simply your desired model with a GPU workload type using either the Model Serving UI or the CRUD API. Any model can be served on CPU, GPU, or both workload types.
Infra-as-code for MLOps
It provides a template or reference implementation to create a production-ready MLOps solution on Databricks. The template set up all elements required to implement and operate ML in production including ML pipelines, feature store, inference endpoints, model monitoring, and release pipeline for continuous deployment across multiple environments.
AI Function Serving
Data analysts and data engineers can now use LLMs and other machine learning models within an interactive SQL query or SQL/Spark ETL pipeline. With AI Functions, an analyst can perform sentiment analysis or summarize transcripts–if they have been granted permissions in the Unity Catalog and AI Gateway. Similarly, a data engineer could build a pipeline that transcribes every new call center call and performs further analysis using LLMs to extract critical business insights from those calls.
Curated models by Databricks
Rather than spending time researching the best open source generative AI models for your use case, you can rely on models curated by Databricks experts for common use cases. Our team continually monitors the landscape of models, testing new models that come out for many factors like quality and speed. We make best-of-breed foundational models available in the Databricks Marketplace and task-specific LLMs available in the default Unity Catalog. Once the models are in your Unity Catalog you can directly use or fine-tune them with your data.
See webpage link with side-by-side comparison of models by recommended use case here:
https://www.databricks.com/product/machine-learning/large-language-models-oss-guidance
Inference Tables
All the incoming requests and outgoing responses to serving endpoints are logged to Delta tables in your Unity Catalog. This automatic payload logging enables teams to monitor the quality of their models or functions in near real-time.
Mlflow AI gateway
Help organizations centrally manage usage of models APIs (cost attribution, rate limiting, credential management).
For more information, check out this blog.
Did you miss a session ? It’s ok recording from the 250 sessions are available on demand in
the Data+AI summit platform.